Coding Workflow August 2025
Importance: 5 | # | mine, ai-coding
There's a barrage of coding-AI tools coming out every day and plenty of fancy workflows being discussed. This is my workflow as of August 2025. I primarily work on medium-sized Python codebases (~100k LOC). I also build little tools and work with small repos. Unless explicitly stated, everything here is about features/changes to larger production codebases. I'll first outline the mental models I use for coding with AI and then detail my current workflow.
Mental Model
It helps to frame the problem as optimizing work-throughput (while controlling for quality, creativity, etc.). And I have access to unlimited chimera engineers—eager to help, prone to misinterpreting context, over-engineering, assimilated all of human knowledge, ultra-fast information consumption, massive working memory, and static long-term memory... yeah lots of caveats.
I also think of it as reducing the generation–verification gap as Karpathy puts it (notes). You have this intelligence that can generate output relentlessly; the work is then about guiding generation and verifying effectively.
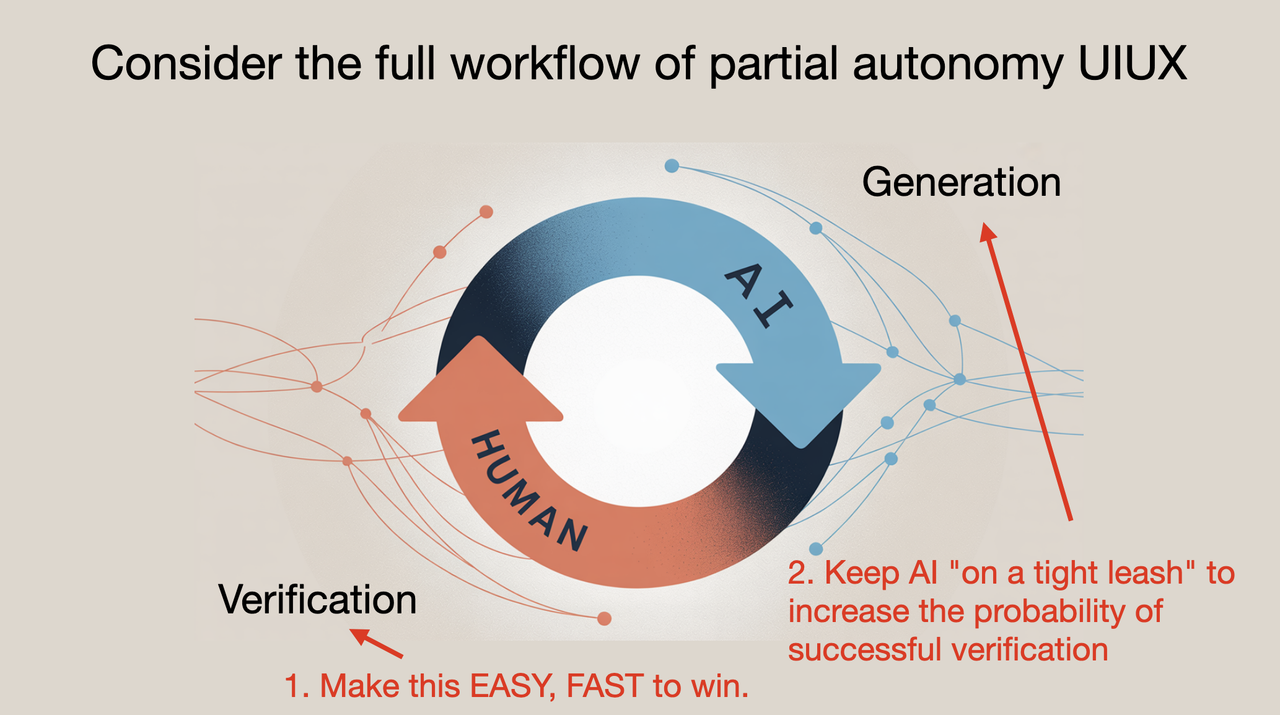
Workflow
My workflow roughly follows these steps:
- Build Giant-Prompt
- Plan (no code) + my-review + iterate
- List of changes (pseudocode) + my-review + iterate
- Diffs implementation + my-review + iterate
- Iterate/test
Context is king.
My workflow is similar to what antirez suggests: I mainly use the chat interface. Given a feature/fix, I figure out the relevant context—files, functions, classes—exactly as I would without AI. I put all of this in a single Markdown file: my Giant-Prompt. If the repo is small enough I use files-to-prompt to dump the entire repo. I assimilate the context necessary to implement the change. Ask - would this be enough if I were sending this prompt to a cracked dev unfamiliar with this repo. This is obviously not a perfect analogy given that the dev will take an hour or a day to get back while the model will in <10min so you can iterate quickly, and the dev does not have phd-level knowledge in all fields. But it is close enough. This part is of course time consuming.
Once I have the Giant-Prompt, I usually pass it to two models side by side—today that's GPT-5-Thinking and Claude 4.1 Opus. First, I ask explicitly not to implement any code and instead give me an overview of how to go about solving the problem at a high level. I discuss pros and cons of design decisions and think through the simplest approach. You should be able to catch any of the major prompt fuckups and tendency for over-enginneering here. Importantly, this is where I figure out what it is that I actually want.
Imagine you have the AI implement a 1000 line diff and after 20 mins of reviewing code you find a logic error and you ask claude-code to fix it and it goes ahead and produces a 500 line diff now and you gotta review the whole thing, and you start screaming at claude as this goes on for longer than if you had just written the damn thing yourself... Might as well spend time upfront aligning the model.
Next, I ask for the list of changes that would have to be done, again not code - sometimes I ask for high level pseudocode. Starting with highlevel changes, then adjusting and subsequently getting into lower level details works best. After some iterations I ask for the implementation - list of changes to be made. Sometimes in this process I'll start fresh chats (clean context) with modified Giant-Prompt. If testing with a script makes sense, I have the model write that as well.
At this point I either make the changes myself or paste the output into claude code and have it apply the diff — no intelligence required. Then I review the diffs thoroughly, understand exactly what's happening, and own the code. I keep the chat thread/s handy at this stage and ask any questions I have, modifications to the code,...
As I review, I keep prompting the chat threads to review as well, I usually ask to look for bugs, consistency issues, logic errors, edgecases missed and gotchas. This is super useful.
This workflow might not necessarily increase throughtput by itself, but it massively helps to not just sit around or scroll through twitter while the response is being generated. There's always shit to do (even without context switching) during the generation time - reading detailed outputs, reading code, thinking through, reading the other AI's output...
I tried agents (mainly Claude Code), really tried. It's not that they don't work; it's that the output-to-effort ratio isn't there yet given today's capabilities and scaffolding. They're great for vibe-coding where you don't need to read the code and can just run things. The tools do not do justice to the intelligence/capabilities of the models - they read files in little chunks and struggle. It is not the best way to get things done right now - more hand holding and supervision is required. The models need to be kept on a tighter leash.
Tools
These are the tools I mainly use:
- GPT-5-Thinking, GPT-5-Pro, Claude 4.1 Opus for chat (rarely Gemini 2.5 Pro now that GPT-5 has a 1M context window, kinda sad personally for me, 2.5-pro was a beast of an upgrade in march).
- Cursor — just for Cursor Tab. I never use the Cursor agent. Cmd+K is occasionally useful, but I almost always go to the chat interface.
- Claude Code/Codex (only to do basic things or understand codebase)
A lot of people shoot themselves in the foot expecting AI to read their mind. In a way they lack empathy for the AI (understandably), if one puts some effort into imagining what it would really be like to not know anything specific to you or your problem statement, that itself would go a long way.
Building intuition for what a model will nail versus what will trip it up is super useful and comes from time spent with the models. Good investment to make, no wall in sight.