Hi! Here I post links of interesting things I find. You can click on link below each post to go to the link.
Posts
-
Coding Workflow August 2025
Importance: 5 | # | mine, ai-coding
There's a barrage of coding-AI tools coming out every day and plenty of fancy workflows being discussed. This is my workflow as of August 2025. I primarily work on medium-sized Python codebases (~100k LOC). I also build little tools and work with small repos. Unless explicitly stated, everything here is about features/changes to larger production codebases. I'll first outline the mental models I use for coding with AI and then detail my current workflow.
Mental Model
It helps to frame the problem as optimizing work-throughput (while controlling for quality, creativity, etc.). And I have access to unlimited chimera engineers—eager to help, prone to misinterpreting context, over-engineering, assimilated all of human knowledge, ultra-fast information consumption, massive working memory, and static long-term memory... yeah lots of caveats.
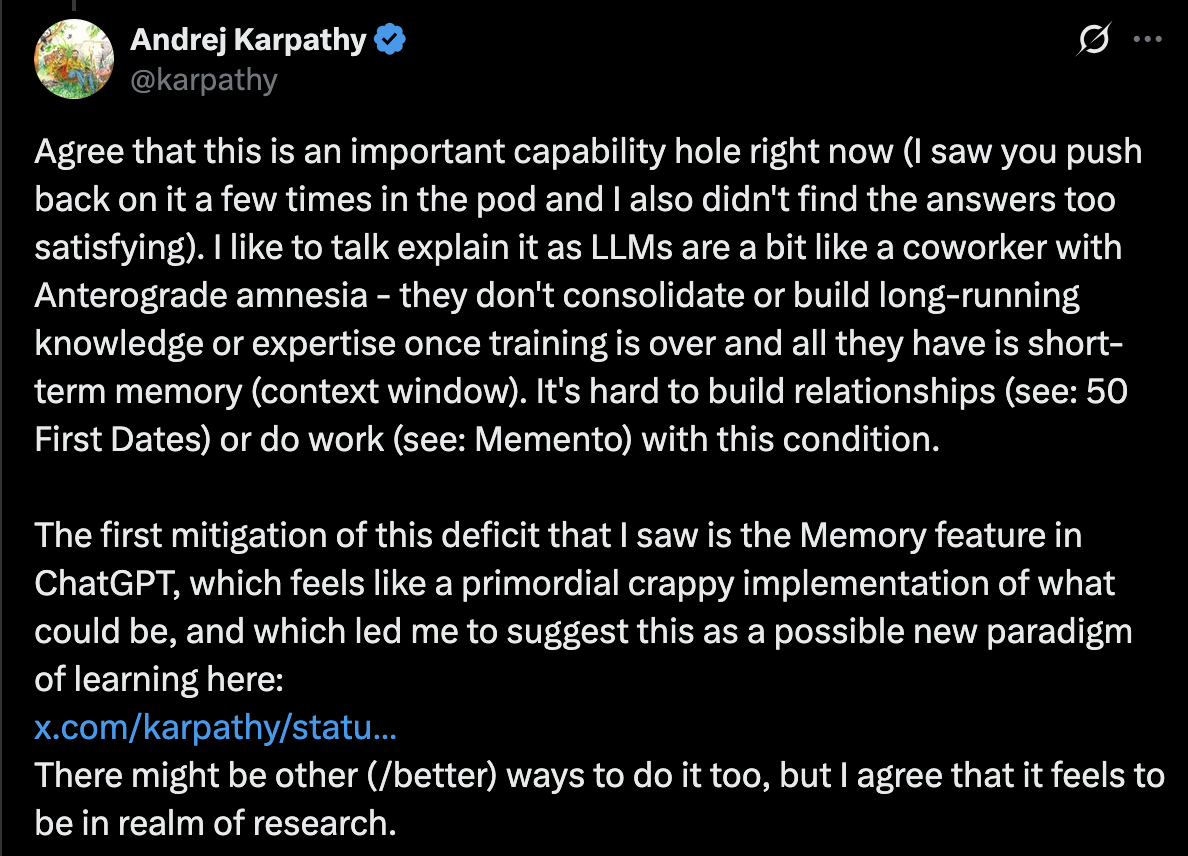
I also think of it as reducing the generation–verification gap as Karpathy puts it (notes). You have this intelligence that can generate output relentlessly; the work is then about guiding generation and verifying effectively.
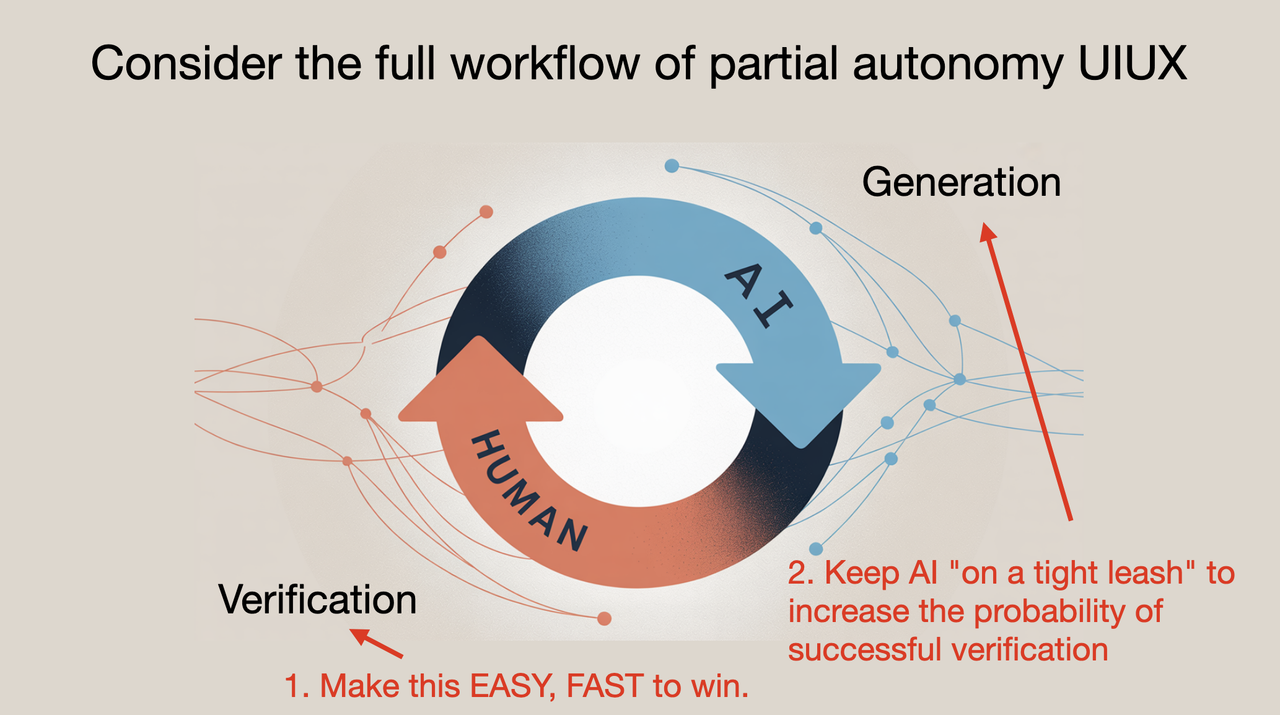
Workflow
My workflow roughly follows these steps:
- Build Giant-Prompt
- Plan (no code) + my-review + iterate
- List of changes (pseudocode) + my-review + iterate
- Diffs implementation + my-review + iterate
- Iterate/test
Context is king.
My workflow is similar to what antirez suggests: I mainly use the chat interface. Given a feature/fix, I figure out the relevant context—files, functions, classes—exactly as I would without AI. I put all of this in a single Markdown file: my Giant-Prompt. If the repo is small enough I use files-to-prompt to dump the entire repo. I assimilate the context necessary to implement the change. Ask - would this be enough if I were sending this prompt to a cracked dev unfamiliar with this repo. This is obviously not a perfect analogy given that the dev will take an hour or a day to get back while the model will in <10min so you can iterate quickly, and the dev does not have phd-level knowledge in all fields. But it is close enough. This part is of course time consuming.
Once I have the Giant-Prompt, I usually pass it to two models side by side—today that's GPT-5-Thinking and Claude 4.1 Opus. First, I ask explicitly not to implement any code and instead give me an overview of how to go about solving the problem at a high level. I discuss pros and cons of design decisions and think through the simplest approach. You should be able to catch any of the major prompt fuckups and tendency for over-enginneering here. Importantly, this is where I figure out what it is that I actually want.
Imagine you have the AI implement a 1000 line diff and after 20 mins of reviewing code you find a logic error and you ask claude-code to fix it and it goes ahead and produces a 500 line diff now and you gotta review the whole thing, and you start screaming at claude as this goes on for longer than if you had just written the damn thing yourself... Might as well spend time upfront aligning the model.
Next, I ask for the list of changes that would have to be done, again not code - sometimes I ask for high level pseudocode. Starting with highlevel changes, then adjusting and subsequently getting into lower level details works best. After some iterations I ask for the implementation - list of changes to be made. Sometimes in this process I'll start fresh chats (clean context) with modified Giant-Prompt. If testing with a script makes sense, I have the model write that as well.
At this point I either make the changes myself or paste the output into claude code and have it apply the diff — no intelligence required. Then I review the diffs thoroughly, understand exactly what's happening, and own the code. I keep the chat thread/s handy at this stage and ask any questions I have, modifications to the code,...
As I review, I keep prompting the chat threads to review as well, I usually ask to look for bugs, consistency issues, logic errors, edgecases missed and gotchas. This is super useful.
This workflow might not necessarily increase throughtput by itself, but it massively helps to not just sit around or scroll through twitter while the response is being generated. There's always shit to do (even without context switching) during the generation time - reading detailed outputs, reading code, thinking through, reading the other AI's output...
I tried agents (mainly Claude Code), really tried. It's not that they don't work; it's that the output-to-effort ratio isn't there yet given today's capabilities and scaffolding. They're great for vibe-coding where you don't need to read the code and can just run things. The tools do not do justice to the intelligence/capabilities of the models - they read files in little chunks and struggle. It is not the best way to get things done right now - more hand holding and supervision is required. The models need to be kept on a tighter leash.
Tools
These are the tools I mainly use:
- GPT-5-Thinking, GPT-5-Pro, Claude 4.1 Opus for chat (rarely Gemini 2.5 Pro now that GPT-5 has a 1M context window, kinda sad personally for me, 2.5-pro was a beast of an upgrade in march).
- Cursor — just for Cursor Tab. I never use the Cursor agent. Cmd+K is occasionally useful, but I almost always go to the chat interface.
- Claude Code/Codex (only to do basic things or understand codebase)
A lot of people shoot themselves in the foot expecting AI to read their mind. In a way they lack empathy for the AI (understandably), if one puts some effort into imagining what it would really be like to not know anything specific to you or your problem statement, that itself would go a long way.
Building intuition for what a model will nail versus what will trip it up is super useful and comes from time spent with the models. Good investment to make, no wall in sight.
-
What Is Man, That Thou Art Mindful Of Him?
Importance: 5 | # | acx, ai
God: …and the math results we’re seeing are nothing short of incredible. This Terry Tao guy -
Iblis: Let me stop you right there. I agree humans can, in controlled situations, provide correct answers to math problems. I deny that they truly understand math. I had a conversation with one of the humans recently, which I’ll bring up here for the viewers … give me one moment …
When I give him a problem he’s encountered in school, it looks like he understands. But when I give him another problem that requires the same mathematical function, but which he’s never seen before, he’s hopelessly confused.
Funny and beautiful.
-
Mass Intelligence
Importance: 4 | # | ethan-mollick, openai, ai
There have been two barriers to accessing powerful AI for most users. The first was confusion. Few people knew to select an AI model. Even fewer knew that picking o3 from a menu in ChatGPT would get them access to an excellent Reasoner AI model, while picking 4o (which seems like a higher number) would give them something far less capable. According to OpenAI, less than 7% of paying customers selected o3 on a regular basis, meaning even power users were missing out on what Reasoners could do.
Another factor was cost. Because the best models are expensive, free users were often not given access to them, or else given very limited access. Google led the way in giving some free access to its best models, but OpenAI stated that almost none of its free customers had regular access to reasoning models prior to the launch of GPT-5.
GPT-5 was supposed to solve both of these problems, which is partially why its debut was so messy and confusing. GPT-5 is actually two things. It was the overall name for a family of quite different models, from the weaker GPT-5 Nano to the powerful GPT-5 Pro. It was also the name given to the tool that picked which model to use and how much computing power the AI should use to solve your problem
-
Are OpenAI and Anthropic Really Losing Money on Inference?
Importance: 4 | # | llm
I'm only going to look at raw compute costs. This is obviously a complete oversimplification, but given how useful the current models are - even assuming no improvements - I want to stress test the idea that everyone is losing so much money on inference that it is completely unsustainable.
Martin makes some rough calculations - starting with deepseek V3 as baseline and taking into account hourly rate of H100s and assuming bandwidth bound process (3.35 TB/s HBM badnwidth) - calculates number of forward passes per second. Two seperate calculations for prefill and decode stage and here's the outcome:
The asymmetry is stark: $144 ÷ 46,800M = $0.003 per million input tokens versus $144 ÷ 46.7M = $3.08 per million output tokens. That's a thousand-fold difference!
Of course the prefill stage can become compute bound at long context lengths.
These costs map to what DeepInfra charges for R1 hosting, with the exception there is a much higher markup on input tokens.
By these numbers, there is good chance that even the claude-max plan for claude-code users are running at a 10x markup for heavy users - costing $20 and charging $200.
One interesting point here is how Anthropic and OpenAI differ in their approach to models. Judging for raw token speed, my guess would be that Claude models are larger but token efficient (Opus 4.1 barely thinks and is competitive with say GPT-5-thinking-high), whereas GPT5 without thinking (minimal) is a pretty dumb model and for high quality outputs it thinks forever. If each output token is so costly, and OpenAI was supposedly optimizing for inference cost - wouldn't they have gone for a model like Claude? One explanation is that these estimates are assuming MOE model with like 5% active parameters, it could be that Claude is either much higher active params or not MOE at all. It will be interesting to see what approach people take moving forward - Anthropic doesn't need to optimize for inference as much as OpenAI - no free users.
-
In Search Of AI Psychosis
Importance: 5 | # | acx, ai-psychosis
AI psychosis (NYT, PsychologyToday) is an apparent phenomenon where people go crazy after talking to chatbots too much. There are some high-profile anecdotes, but still many unanswered questions. For example, how common is it really? Are the chatbots really driving people crazy, or just catching the attention of people who were crazy already? Isn’t psychosis supposed to be a biological disease? Wouldn’t that make chatbot-induced psychosis the same kind of category error as chatbot-induced diabetes?
I don’t have all the answers, so think of this post as an exploration of possible analogies and precedents rather than a strongly-held thesis. Also, I might have one answer - I think the yearly incidence of AI psychosis is somewhere around 1 in 10,000 (for a loose definition) to 1 in 100,000 (for a strict definition). I’ll talk about how I got those numbers at the end.
Scott conducts a survey (4156 responses - they are asked to estimate psychosis rate among friends and family) and estimates loose psychosis rate at 1 in 10,000 - rate of all people who get pushed to psychosis and a strict rate of 1 in 100,000 - people who showed no signs/risks of psychosis pre-AI-use and get pushed to psychosis.
-
Google will require developer verification to install Android apps, including sideloading
Importance: 7 | # | google
To combat malware and financial scams, Google announced today that only apps from developers that have undergone verification can be installed on certified Android devices starting in 2026.
-
How to think in writing
Importance: 6 | # | henrik-karlsson, writing, thinking
When I sit down to write, the meadow is still engulfed in darkness under a sky where satellites pass by, one after the other. My thoughts are flighty and shapeless, like dreams; they morph as I approach them. But when I open my notebook and write, it is as if I pin my thoughts to the table. I can examine them. ...
Since the goal is to find flaws in our guesses (so that we can change our minds, refine our mental models and our language, and be more right) stretching a claim thin through an explanation is progress. Even if the explanation is wrong.
You are interested only in proofs which ‘prove’ what they have set out to prove. I am interested in proofs even if they do not accomplish their intended task. Columbus did not reach India but he discovered something interesting. —Lakatos
Super useful and well written as always. Henrik provides a couple of concrete techniques to write for thinking better:
- go as far as possible with an idea/hypothesis/conjecture you have and make a strong and concrete case for it
- concrete is important because the core value of writing comes from pinning down thoughts - handwaving possibilites should be minimized
- you are not looking to be right, you are looking to learn and refine your ideas
- the mere act of having to concretely write down the idea and put thoughts into words is a lot of effort and is fruitful by itself and you have concrete words etched in ink or silicon to hold yourself accountable
- find counter examples
I make extensive use of the counter examples technique. I try to lay down a hypothesis and then think of counter evidence. Kinda comes naturally after having scrolled through hackernews comments for so long now.
Writing down concrete ideas while trying to reduce ambiguity is not something I do concisouly. I am usually trying to accurately represent my state of mind. And as the state evolves so does the ink. I do spread ideas thin - but it's handwavy a lot of the times. Henrik provides plenty of examples where one escapes ones own words by handwaving away what they actually meant. I observe this with myself as well. Making a concious effor to minimize this should bode well.
It is useful to take a hypothesis and make as strong a case for it as possible, write it down, leave little room for ambiguity. Then find counter evidence, refine, repeat. This is usually how anyone hardens ideas. Very bayesian. It is also useful to do this when you think the idea is wrong or only right in 80% of the cases. Wrong ideas are ofcourse worth writing and talking about.
Gwern has a confidence tag - to indicate how likely he thinks it is that the ideas in the post are to be true. There's also a lesswrong post/comment about how simple ideas that explain say 80% of observations and cannot account for the rest are super useful - I can't find it right now.
- go as far as possible with an idea/hypothesis/conjecture you have and make a strong and concrete case for it
-
P(doom) vs P(permanent underclass)
Importance: 4 | # | zvi, agi, post-agi
zvi:
Jordi Hays: I'm updating my timelines. You now have have at least 4 years to escape the permanent underclass.
Luke Metro: This is the best news that founding engineers have received in years.
Nabeel Qureshi: The 'vibe shift' on here is everyone realizing they will still have jobs in 2030.
(Those jobs will look quite different, to be clear...)
It's a funny marker of OpenAI's extreme success that they released what is likely going to be most people's daily driver AI model across both chat and coding, and people are still disappointed.
Part of the issue is that the leaps in the last two years were absolutely massive (gpt4 to o3 in particular) and it's going to take time to work out the consequences of that. People were bound to be disappointed eventually.
Zvi: On the question of economic prospects if and when They Took Our Jobs and how much to worry about this, I remind everyone that my position is unchanged: I do not think one should worry much about being in a ‘permanent underclass’ or anything like that, as this requires a highly narrow set of things to happen - the AI is good enough to take the jobs, and the humans stay in charge and alive, but those humans do you dirty - and even if it did happen the resulting underclass probably does damn well compared to today.
You should worry more about not surviving or humanity not remaining in control, or your place in the social and economic order if transformational AI does not arrive soon, and less about your place relative to other humans in positive post-AI worlds.
So how likely is the scenario that (most people + you lose your jobs to AI) AND (powerful people decide to fuck over everyone else) AND (AI good enough to do all of human labour does not kill us all)? We can ignore the issue of the underclass having a way better quality of life - should come included in the second event.
-
Claude Sonnet 4 now supports 1M tokens of context
Importance: 4 | # | anthropic, claude
Claude Sonnet 4 now supports up to 1 million tokens of context on the Anthropic API—a 5x increase that lets you process entire codebases with over 75,000 lines of code or dozens of research papers in a single request.
Long context support for Sonnet 4 is now in public beta on the Anthropic API and in Amazon Bedrock, with Google Cloud’s Vertex AI coming soon.

Anthropic has kinda cucked themselves here with their pro and max plans. The claude-code users will leave them bleeding dry if 1M context is brought to claude-code. It wouldn't be surprising if they had this ready for a while but couldn't figure out how to manage costs and now it's a bit too late and they are weirdly releasing for API only and not for subscribers.
Opus is good model. It isn't a reasoning model in the way openai's or google's are. Opus rarely thinks long and is super token effecient in general. Test time scaling is least used with Opus comared to other frontier models. It's crazy that this almost-not-a-reasoning-model is one of the very best right now.
Fitting everything into the 200k context while being super useful requires that you have high token efficiency - especially for code. Given that this is the first time we are seeing 1M context from Anthropic, it wouldn't be surprisnig if they are working on reducing inference cost by decreasing the model size and increasing test-time-compute.
I am also curious about how these 1M models are trained. So we have had 4.1 sonnet for a while now and they presumably took the 200k context length model and subsequently trained it on larger sentences? But then this would definitely affect the model behaviour even at smaller context lengths. It would make so much more sense if they leave the current model as is and release this new model with a different number - 4.2.
-
Qwen3-4B-Thinking: “This is art—pelicans don’t ride bikes!”
Importance: 4 | # | simonw, qwen, slm
These are relatively tiny models that punch way above their weight.
I used the Instruct model to summarize this Hacker News conversation about GPT-5.
The good news is Qwen spat out a genuinely useful summary of the conversation! You can read that here—it’s the best I’ve seen yet from a model running on my laptop, though honestly I’ve not tried many other recent models in this way.
The bad news... it took almost five minutes to process and return the result!
They’re fun, they have personality and I’m confident there are classes of useful problems they will prove capable at despite their small size. Their ability at summarization should make them a good fit for local RAG, and I’ve not started exploring their tool calling abilities yet.
I tried the model locally (ollama) and on openrouter. A 4B model that runs on a phone with some (unreliable) intelligence is insane. If it can do something well - like if it could just summarize reliably - that would be huge. In practice when you want to make use of intermediate LLMs between user request and response, the latency become super crucial - and although providers like groq and cerebras can push 1000+tok/s, the time-to-first-token becomes the bottleneck. A model small enough to easily host on a server you can control could solve this to an extent.
More here.
Say hello.